
WIDEプロジェクトはさまざまな産学組織の研究者・技術者・運用者から成り立っています。組織の枠を超えたつながりの中で、インターネットをはじめとする広域分散処理技術を中心に、より便利で安全な未来を目指した技術開発と研究が進められています。ここでは、その中から若手研究者が取り組んでいる研究課題を取り上げ、これから世に出ていく新しい技術と、その研究開発に取り組む姿を紹介します。
より高度で柔軟なトラフィックエンジニアリングやサービスファンクションチェイニングなどへの応用に向けて、新しい経路制御技術であるセグメントルーティングが注目を集めています。今回はその次世代経路制御技術に興味を持ち、セグメントルーティングが抱える規模性の解決に取り組む研究者を紹介します。

北陸先端科学技術大学院大学
篠田研究室 修士課程 三島 航(みしま わたる)
北陸先端科学技術大学院大学 篠田研究室 修士2年の三島航です。セグメントルーティングにおける階層化について研究を行なっています。WIDEプロジェクトには2017年の7月から参加しています。 WIDEでの主な活動としては、2018年春の研究会でインフラワークショップ開催、秋合宿で会場ネットワーク構築・ポスター発表を行いました。その他の活動としては、2018年のInterop ShowNetにSTMとして参加しました。普段の生活でも研究室ネットワークの管理・運用を行なっています。
セグメントルーティング(以下、SR)とは、経路の各要素をセグメントと呼ばれる単位で表現し、経由先や宛先として指定することで柔軟な制御を実現する技術です。SRはシンプルかつ柔軟な経路制御技術として、トラフィックエンジニアリングやサービスチェイニングなどでの利用が期待されています。以下にSRの概念図を載せます。

SRではセグメントを表すため、セグメントID(SID)と呼ばれる識別子を用います。送信元ノードで、セグメントリストと呼ばれる経由セグメントのSIDリストをパケットに付加することで経路を指定し、転送を行うソースルーティングの一種です。
セグメントにはノードを示すNodeセグメントと、隣接関係を示すAdjacencyセグメントの二種類が存在します。Node SIDが指定された場合はそのノードへのアンダーレイネットワークにおける最短経路を用い転送が行われます。Adjacency SIDが指定された場合、Adjacency SIDが示すインターフェースから送出が行われます。
上の図にSRにより転送を行う様子を示しました。この例は、8番から5番のノードへと送信するパケットを、最短経路ではなく4、1のノードを経由するように経路制御した例となります。そのため転送対象のパケットに「8-4、1、5」というセグメントリストを付加しています。
SRに参加するノードの集合をSRドメインと呼びます。各ノードはSRドメインに参加する全ノードのNode SIDと、自らのインターフェースのAdjacency SIDを格納したSIDテーブルを保持しています。各ノードは受け取ったパケットのセグメントリストの先頭要素を確認し、SIDテーブルを参照することで次の宛先を決定し、送出を行います。
SRの問題点として、各ノードがSRドメインの全ノード分のNode SIDをSIDテーブルに持たなければならない点があります。これにより、参加ノードが増加すると各ノードが持つべきSIDテーブルの情報量が増加し、メモリ量と検索時間の負荷による規模性の問題が生じます。この対策として、私の研究ではSRの階層化を提案しています。提案手法である階層的SRの概念図を以下に示します。

左側が既存のSR、右側が階層的SRを示しています。階層的SRではSRドメインをサブドメインに分割し、各ノードに自らの属するサブドメイン内の情報のみを持たせることで情報量を削減し、規模性を確保します。図の例では、23番のノードはサブドメインC内部の21、22、24の情報のみに抑制できます。
情報量を削減した上で正しく転送を行うため、本研究では二種類の手法を提案しました。 以下にそれぞれの概念図を示します。

1つ目は上位SIDモデルです。このモデルでは各サブドメインにSIDを付与し、経由先として指定することでサブドメインを超えた転送を可能にします。図の例では、サブドメインにそれぞれ0、10、20というSIDを付与しています。このモデルはで上位SIDを指定可能なため、次に扱う展開モデルに比べセグメントリストを短く構成することが可能になりますが、サブドメインに付与したSIDを扱えるようデータプレーンの拡張が必要となります。
2つ目は展開モデルです。このモデルでは各ノードがサブドメイン内の情報のみで転送を行えるよう、セグメントリストを構築します。図の例では、23のノードはサブドメイン内の22へ、22のノードはAdjacency SIDを用い隣のサブドメインへ、というようにサブドメイン内の情報のみで転送する様子を示しています。このモデルでは既存のSRと同じSIDを利用するため、データプレーンの拡張は不要です。しかしサブドメイン間を移動する際必ずAdjacency SIDを指定する必要があるため、上位SIDモデルに比べセグメントリストは増大します。本研究では、まず実装負荷の低い展開モデルから実装を行なっています。
この研究の面白い要素として、サブドメインサイズとパフォーマンスの兼ね合いや、アンダーレイプロトコルの規模性との兼ね合いなど、実際に動かしてみないとわからない要素が多い点があります。また、SRは新しいトピックであり、手を動かすことで切り開いていくというやりがいも大きいです。
現在、OSSのルーティングデーモンであるFRRoutingとLinux KernelのMPLSで実装を開始しています。今後は修了までに階層的SRの実装と評価を進めていきます。またその中で、MPLS-TEやSRv6なども扱って行きたいと考えています。進捗や調査項目などは研究ページ(https://watal.github.io/)に随時更新していきます。 FRRoutingを用いた実験方法を記事にまとめているので、ぜひ試してみてください。
(2018年12月)
次回は北陸先端科学技術大学院大学の宮崎駿さんの研究を紹介します。
自動車の情報化はめざましい勢いで進んでいます。今後はより強固にインターネットと接続し、高度なサービスを提供するようになるでしょう。パソコンなどと違い、自動車では小さな不具合が人命に関わる事故につながることがあります。安全なネット接続は必須条件です。今回は、自動車の高度化を推進しながら、安全なネットサービスの実現を目指す研究者を紹介します。

北陸先端科学技術大学院大学
篠田研究室 修士課程 宮崎 駿(みやざき しゅん)
北陸先端科学技術大学院大学 篠田研究室 修士2年の宮崎駿です。自動車のハニーポットについて研究を行なっています。WIDEプロジェクトには2017年の7月に参加しました。以後、2018年春の研究会運営、研究会での研究成果報告、2018年の秋合宿研究会での会場ネットワーク構築、ポスター発表、またBSD BoFの開催などに取り組んできました。
私は文系学部出身であり、学部時代に自動車の研究をしていた訳ではありませんでした。この研究テーマを思いついたのは修士1年の時です。研究室ゼミで指導教官から、「コンピュータを繋いだら自動車のあらゆるデバイスを不正に操作できる」と教えられ、衝撃を受けたことからこの研究に興味を持ちました。調査を進める中で、実際の自動車を遠隔から操作できることも知りました。その後、車載ネットワークシミュレータについて調査した際に、車載ネットワークがインターネット側から見えるような仕組みを作れば、遠隔攻撃を試みる攻撃者を誘い込むハニーポットになると気がつき、研究に取り掛かりました。
近年、コネクテッドカーなど無線接続によって外部と通信する機能を持つ自動車が増加しており、今後もこの傾向は続くと予想されます。これによって車載ネットワークに対する遠隔からのサイバー攻撃が懸念されます。遠隔から車載ネットワーク内部に不正なメッセージを送信することで、ステアリングやブレーキなどに対する不正な操作が可能であることはすでに実験で実証されています。自動車への攻撃は車内・車外の人々の安全を脅かすものであるため、車載ネットワークへの遠隔攻撃に備えたセキュリティ対策が必要不可欠です。
研究では、セキュリティ対策のためのひとつのアプローチとして自動車のハニーポットを提案しています。自動車のハニーポットとは、インターネットから車載ネットワークに模した環境へのアクセスを提供し、攻撃者に対しては、あたかもその先に本当の車載ネットワークがあるかのように見せつつ、車載サービスを提供する仮想環境と監視機構を用意したものです。
ハニーポットの作成にあたり、インターネットに接続する可能性のある自動車のアタックサーフェスを整理しました。以下にその概念図を示します。
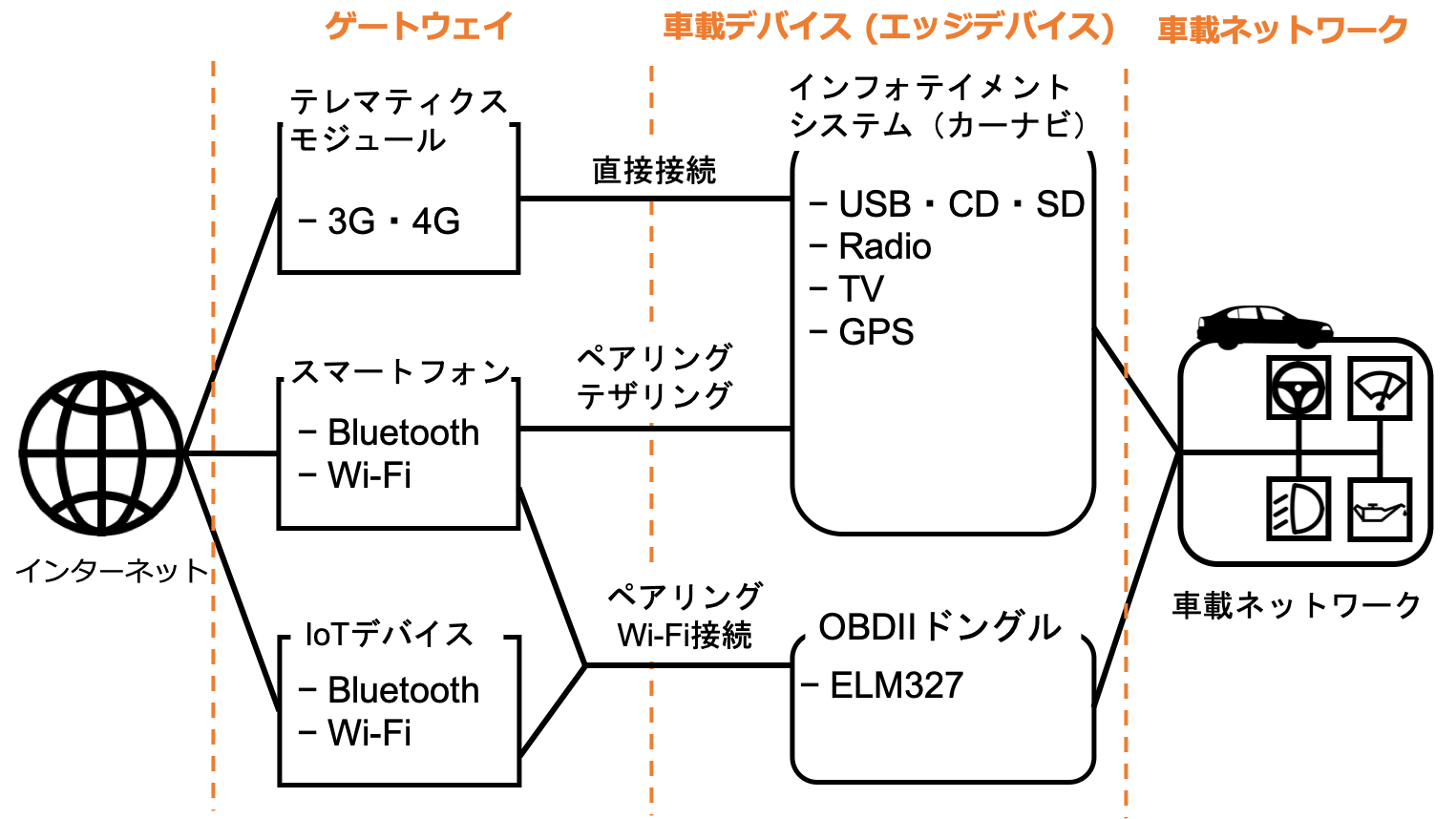
インターネットに接続する可能性のある車載デバイス(エッジデバイス)として、インフォテイメントシステムとOBD-IIドングルが挙げられます。インフォテイメントシステムはスマートフォンのテザリングや3G・4Gのような通信機能を経由してインターネットに接続している可能性があります。一方、OBD-IIドングルの場合は、ELM327のようなドングルを用いてインターネットに接続している可能性があります。
OBD-IIとは自動車の診断を行うことを目的としたコネクタのことです。このコネクタになんらかのドングルを接続することで車載ネットワーク内のデータを読み書きすることができます。Wi-Fiインタフェースを備えたELM327の場合、ELM327自身がWi-Fiアクセスポイントとなります。そこにWi-Fi経由で端末を接続し、ELM327の持つIPアドレスと特定のポート番号にtelnetで接続、任意のコードを入力することで車載ネットワーク内のデータを操作できます。
ここで重要なことは、インターネット側から車載ネットワークにアクセスするには必ずゲートウェイと車載デバイスに相当する2つの機器を経由する必要があるということです。
自動車のアタックサーフェスを参考にハニーポットの構成モデルを考えたものが以下の表になります。
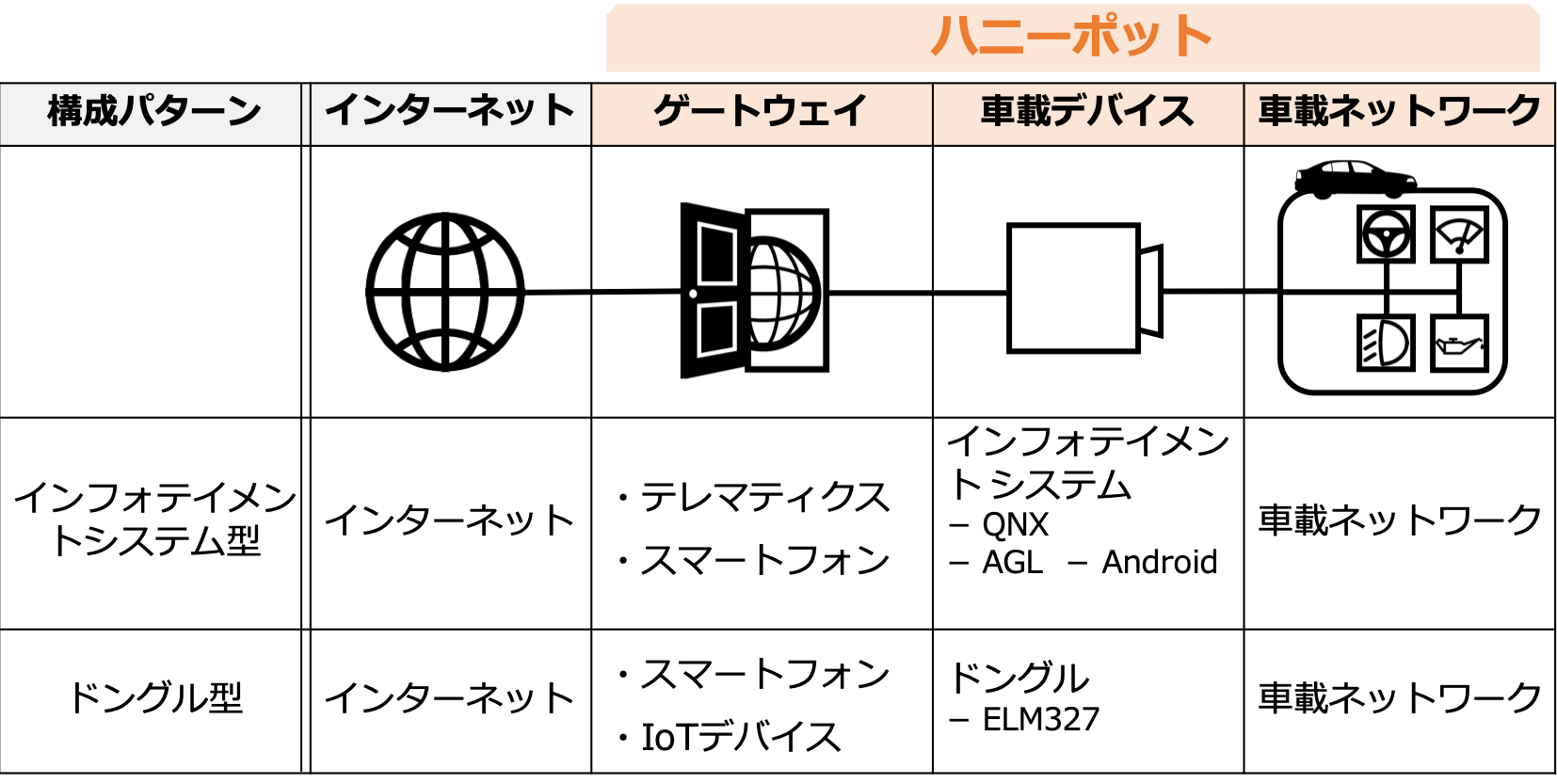
ハニーポットの構成要素はゲートウェイ・車載デバイス・車載ネットワークの3つです。車載デバイスの種類によって、インフォテイメントシステム型とドングル型の2つの構成モデルがあります。インフォテイメントシステム型ではインフォテイメントサービスの基盤としてQNXやAGL(Automotive Grade Linux)などのOSが動作しています。ドングル型では車内ネットワークに流れるデータの受け渡しが可能なドングルが利用されていることを想定しています。
構成モデルを踏まえてハニーポットの実装戦略を考えたものを以下の図に示します。
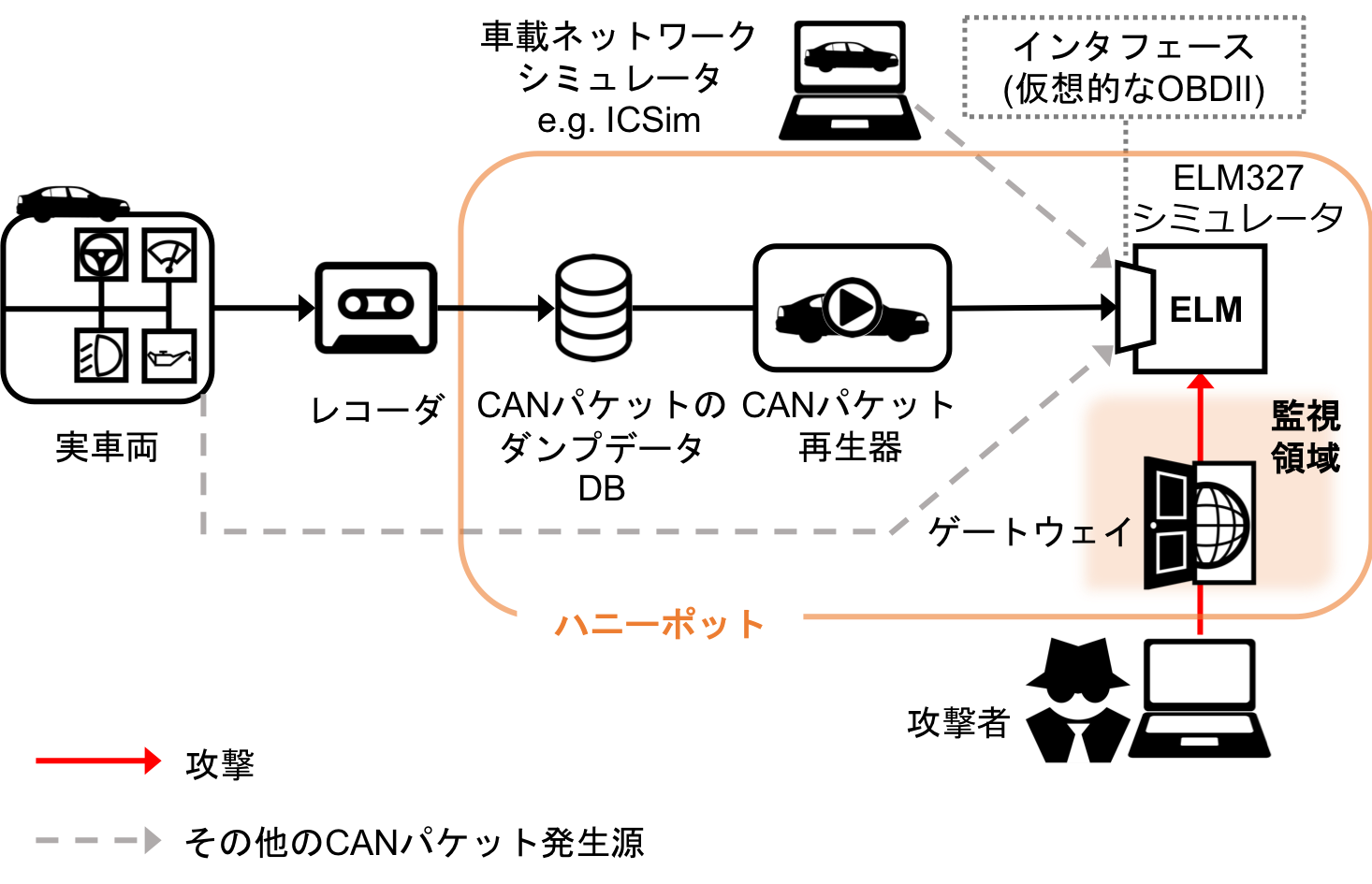
研究では、構成パターンとして実装負荷の少ないドングル型を採用しました。ドングルはELM327を想定しています。車載ネットワークを再現するため、ハニーポットの稼動前に実車両から車載ネットワークに流れるデータをレコーダで記録し、データベースに保存しておきます。ハニーポット稼働時はこの記録したデータを再生機でELM327シミュレータに渡します。この再生機が実車両内に流れるデータを再現します。攻撃者はインターネット側からゲートウェイ機器に接続し、その先にあるELM327シミュレータに接続される仕組みになっています。ELM327シミュレータのインタフェースには再生機の他に、実車両や車載ネットワークシミュレータからデータを渡すことも可能です。
今後、コネクテッドカーやIoT(Internet of Things)などのV2X(Vehicle to everything)技術が発展していく中で、自動車のセキュリティは重要性を増し続けます。現在、自動車への攻撃を捉え、分析するための実装は世の中にはまだありません。そのため誰も見たことのない領域で作業し、研究できる面白さ、楽しさを感じています。また、ハニーポットを作成するにあたっては、攻撃者の車載ネットワークに対する遠隔攻撃プロセスを予測することが必要です。予測した上でより攻撃を誘引しやすいハニーポットの環境はどうあるべきかを考えることは、攻撃者との化かしあいのようなもので面白いです。
現在の実装戦略では攻撃者に対するゲートウェイの見せ方を検討しきれていません。そのため、ゲートウェイがどういった環境であれば攻撃者を誘引できるか、その条件を検討する必要があります。今後、実装戦略で示したドングル型のハニーポットを実装を完成させ、稼働実験、評価していく予定です。
(2019年1月)
次回は名古屋大学の浦野さんの研究を紹介します。
スマートフォンを用いた位置情報の活用は、今や日常生活に欠かせない技術となりました。いつでもどこでも地図と現在位置を確認できるようになり、迷子で遅刻することも少なくなったのではないでしょうか。現在、位置情報はGPS衛星からの電波を観測することで提供されていますが、GPSの電波は地下には届きません。今回は、電波の届かない場所でも正確な位置情報を提供する仕組みに取り組む研究者を紹介します。

名古屋大学大学院
河口研究室 博士課程 浦野 健太(うらの けんた)
名古屋大学大学院 河口研究室D1の浦野です。Bluetooth Low Energy (BLE)を用いた位置推定技術について研究をしています。WIDEプロジェクトには2015年の3月から参加しています。
WIDEでは、2015年春合宿でのUnconferenceにおける発表、春研究会での研究発表、夏合宿でのPCなどを行いました。研究室では日々の研究に加えて、生徒共用のサーバを一部管理しています。
名古屋大学・河口研究室では行動センシング、交通データ解析、コンピュータビジョンなど様々な研究が行われています。どの研究も実世界データを利用しており、人がより快適に生活できる技術の開発を目指しています。今回は、私が取り組むBLEによる位置推定について紹介します。
スマートフォンが普及し、誰でも簡単に自分の位置情報を取得できるようになりました。例えば、地図アプリによる経路案内や、今どこにいるのかのSNS投稿などが挙げられます。実世界の位置を利用するゲームも近年人気を集めています。
これらで利用される位置情報は、主にGPSを利用して取得されています、GPS衛星との通信で地上における自身の位置を特定するのですが、通信状況によっては取得される位置に大きな誤差が生じます。屋外でもビルの多い場所や屋根の下では誤差が大きくなりますが、建物の中・地下街などの屋内では常に誤差が大きいか、そもそも位置が取得できません。そこで、GPSに頼らず位置を推定する方法(=屋内位置推定技術)が研究されています。
屋内位置推定技術により、地下街やショッピングモールにおいて、特定の店までのナビゲーションや、工場内を動くロボットの監視が可能になります。また、人が店内のどの棚の前にいるか、展示会でどのブースの前にいるかなど、興味に関わる情報を取得し、行動分析やマーケティングに利用することも考えられます。
屋内位置推定手法は、推定対象や利用する環境に応じて、加速度や角速度のセンサ信号を使うもの、超音波やレーザを使うもの、RFIDやWi-Fi電波強度を使うものなど多数提案されています。私はそれらの中でもBluetooth Low Energy (BLE)タグを利用したイベント向け位置推定について研究を行っています。
BLEは名前の通りBluetoothの規格の一部で、低消費電力に主眼をおいており、スマートフォンとスマートウォッチの接続や、PCとワイヤレスマウスの接続などに利用されています。また、特定の情報を含むパケットを一定間隔で発信しつづけるBLEビーコンを利用したサービスもあります。
本研究で提案するBLEを利用した位置推定では、BLEビーコンと、BLEビーコンからの電波を受信するスキャナを利用します。位置推定のイメージを下の図に示します。BLEビーコンは人が持ち、スキャナは対象エリアに複数台を分散して設置しておきます。各スキャナは人までの距離に応じて異なる電波強度を観測します。現在はこれらの電波強度から三点測位を行い対象者の位置を推定しています。
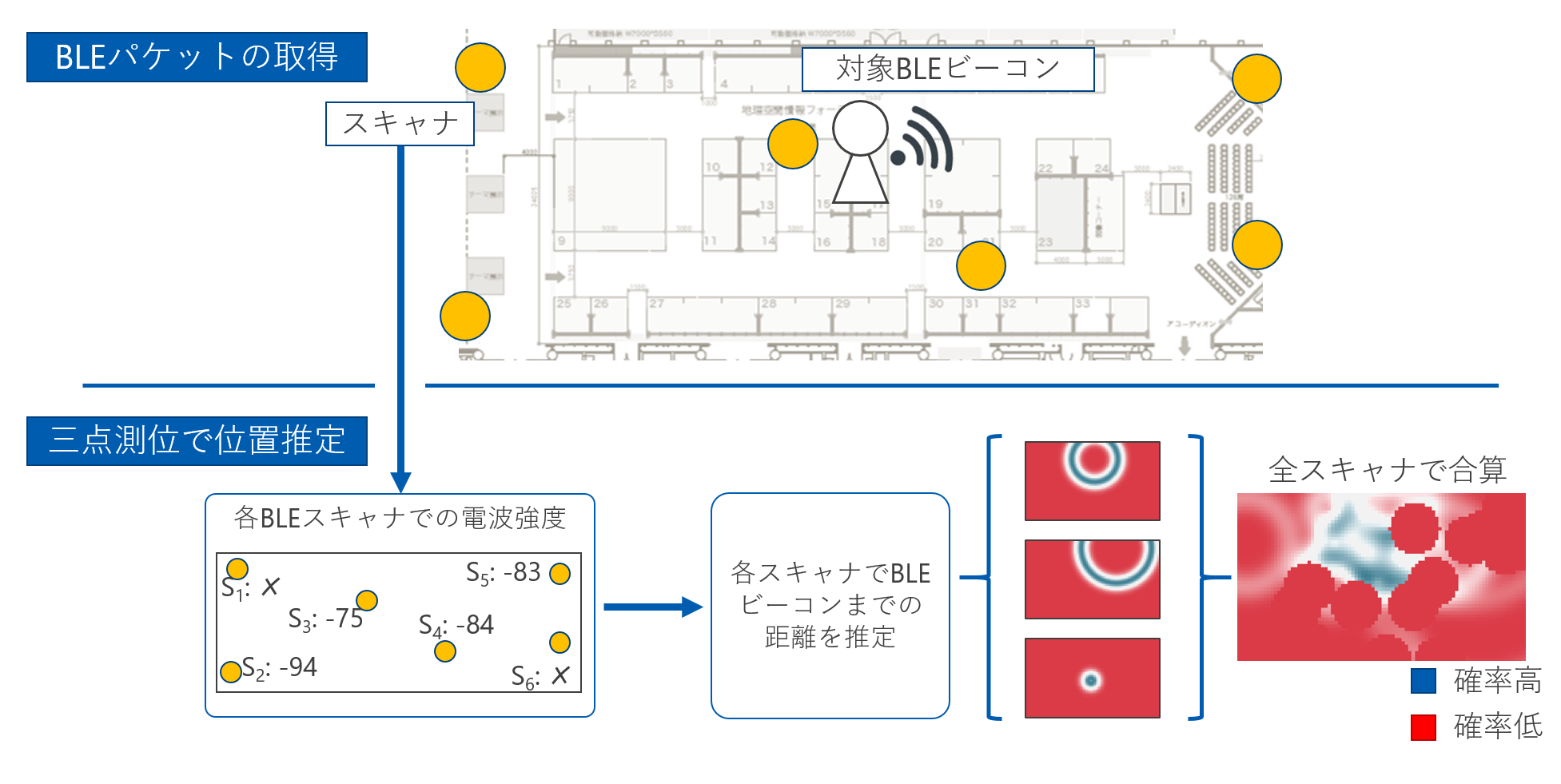
しかし、BLEの電波は不安定で、ノイズや障害物の存在で強度が簡単に変動してしまいます。そこで、本研究では前回の推定位置をもとに、次の推定位置候補となる多数の点(パーティクル)を散布し、尤もらしい位置を探すパーティクルフィルタで安定した推定を目指しています。
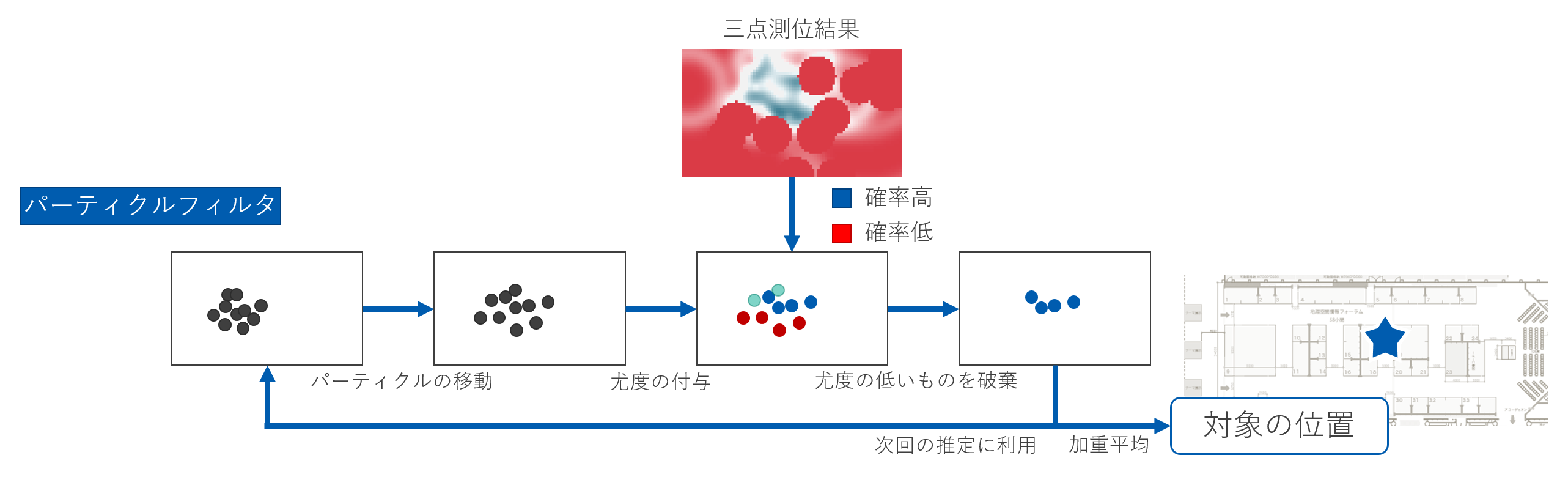
実際に日本科学未来館で行われたイベントにおける位置推定では、反時計回りに会場内を一周する経路で次の図のような結果になりました。図では、青から緑に変わる点が実際の歩行経路を、ピンクから黄色に変わる点が推定した歩行経路を示しています。
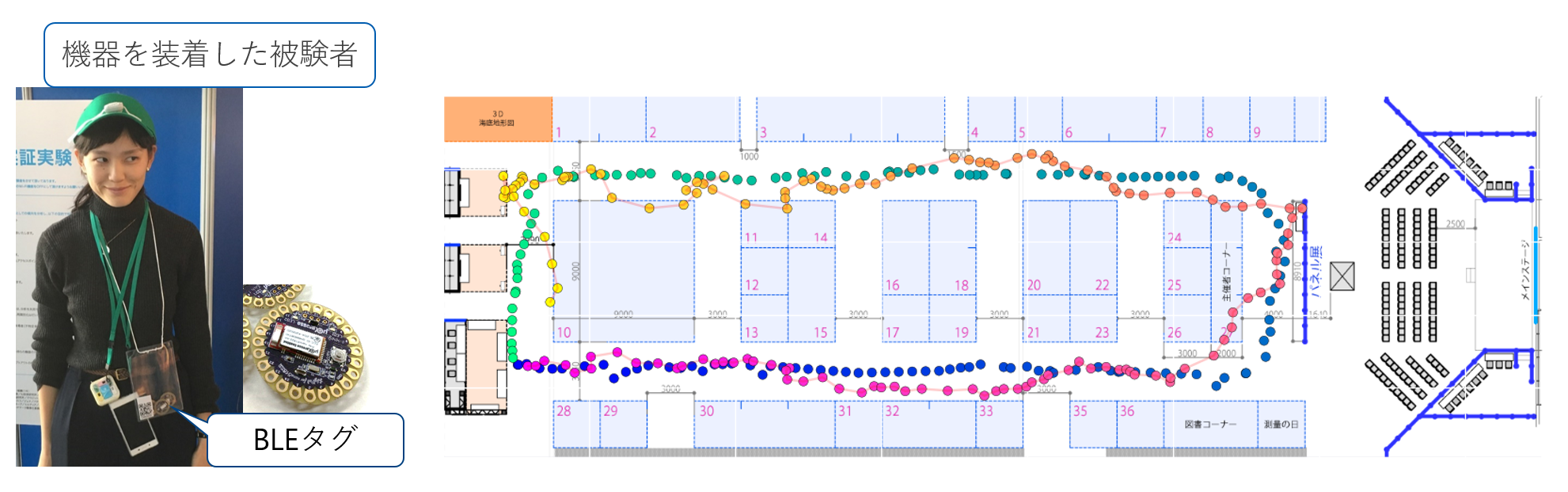
前節でも述べたとおり、BLEの電波は不安定です。強度の変動はもちろん、そもそも電波を受信できない(パケットロス)こともしばしばあります。そこで、ハードウェアの改良として、1つのスキャナに複数のBluetoothアダプタを取り付けたタンデムBLEスキャナを利用し、パケットロスの低減に取り組んでいます(実物は下の図のようになっています)。副次的な効果として、同じパケットを複数のBluetoothアダプタで観測することがあるため、位置推定で利用する電波強度をよりロバストに取得することもでき、精度の向上に繋がりました。

本研究では、アルゴリズム的な部分だけではなく、ハードウェア面でも工夫を施して精度の改善をはかっています。その過程で3Dモデリング/3Dプリンティングや、Raspberry Piなどにも触れており、様々な知識を得られています。電波という目に見えないものを相手にしているので難しい部分も多いですが、工夫の幅も広く、あれこれ試す面白さがあります。
現在はシミュレーションで仮想的に生成した電波強度データで学習したニューラルネットワークを用いて、実際に観測した電波強度データに対する位置推定に取り組んでいます。BLEの電波強度は環境への依存度が大きく、人が移動しなければならないため、大量のデータ収集は困難です。シミュレーションを用いてデータ収集の労力を大きく減らせれば、高精度な位置推定を利用しやすくなると考えられます。
(2019年2月)
悪質なトラフィックを遮断する技術としてパターンマッチなどによるフィルタ技術が広く利用されていますが、より柔軟な対応を実現するため機械学習などの応用が盛んに進められています。ここでは、機械学習など処理負荷の高い技術を、高速ネットワークに応用するための技術に取り組んでいる研究者を紹介します。

東京大学大学院情報理工学系研究科電子情報学専攻
江崎落合研究室 修士課程 須賀 灯希(すが ゆうき)
東京大学大学院 情報理工学系研究科 電子情報学専攻 江崎落合研究室修士2年の須賀灯希です。WIDEプロジェクトには学部4年の時から参加しています。これまで2017年春の研究会でポスター発表を行い、2017年と2018年の秋合宿ではPCとして参加しました。
サイバーセキュリティ分野に興味があり、卒論ではDTLSサーバへのDoS攻撃の対策をテーマとしていました。修士では違うテーマにも取り組みたいと思い、またWIDEの縁でNetwork Muscle Learning (NML) project (Web: https://www.nml.ai) に参加させていただくことになり、現在のテーマになりました。
私の研究テーマは機械学習による悪性トラフィック遮断のための高速パケット分類システムの実現です。巧妙化するサイバー攻撃の検知精度を高めるために、既存のブラックリスト等のパターンマッチングだけでなく、機械学習を用いた攻撃検知手法が近年盛んに研究されています。しかし一般的には機械学習による分類処理はパターンマッチングよりも大きな処理時間を要し、既存研究のほとんどが検知に要する処理時間を考慮していません。また攻撃によるインシデントを未然に防ぐには、ネットワーク上に置かれたファイアウォールのように悪意あるパケットを攻撃対象端末に到着する前に遮断することが肝要です。しかし、通信の良性・悪性判断に時間を要してしまうとネットワークの遅延につながります。こうした背景を踏まえ、本研究ではネットワークの遅延を最小限に抑えつつ機械学習を利用したパケット分類システムの実現を目的としています。
まず予備実験として、図1のような、学習済みモデルを用いた悪性パケット分類システムを構築し性能評価を行いました。本システムはネットワーク上に設置され、受信したパケットから必要な情報を抽出し、それを特徴量ベクトルに変換し学習済み分類器に入力します。そして分類結果に応じて当該パケットを送信または破棄します。システムの実装には、パケット送受信にData Plane Development Kit (DPDK)ライブラリ、分類モジュールとしてRandom Forest (OpenCV)、Support Vector Machine (LIBSVM)、Neural Network (Tensorflow) の3種類の機械学習ライブラリを使用しました。実験では多数のDNSクエリからマルウェアが自動生成 (DGA) した悪性クエリを分類するタスクを設定し、パケット転送時間を計測しました。結果は分類モジュールを組み込まない場合と比較して転送時間が約100倍に増加し、転送時間をスループットに換算すると最大でも10Mbpsとなりました。
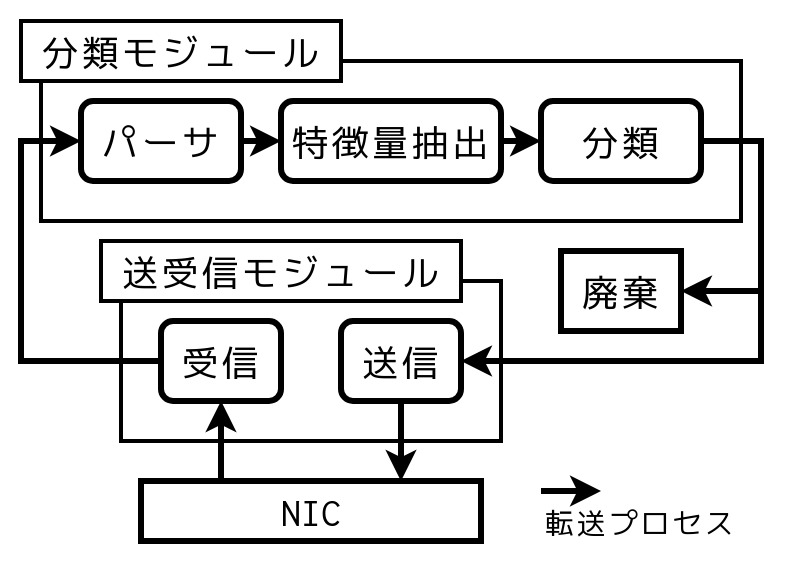
図1 学習済みモデルを用いた悪性パケット分類システム
計測結果を踏まえ、パケット転送遅延をさらに抑えるために、分類対象プロトコルをDNSに絞りDNSの名前解決の仕組みを活用することにしました。DNSの名前解決において、キャッシュサーバがクライアントからクエリを受信し名前解決を行い、結果をクライアントに送信するまでには時間を要します。本研究では名前解決を実施している間に分類処理を実行することを考えました。分類システムをクライアントとキャッシュサーバの間に設置し、クライアントから受信したクエリをキャッシュサーバに転送後、分類処理を名前解決の間に実行し、分類結果に応じてキャッシュサーバからの応答を遮断することで、パケット転送遅延を抑えつつ悪性ドメイン名の名前解決を防止できます。図2に提案システムの概要を示します。システムはクエリを受信後すぐにキャッシュサーバに転送します。その後キャッシュサーバによるクエリの名前解決が行われている間に分類処理を行い、分類結果をブラックリスト・ホワイトリストに反映させます。クエリに対する応答が返ると応答をブラックリスト・ホワイトリストと照合させ、ブラックリストと一致した場合は応答を破棄します。転送処理においてパケットはパーサとフィルタリングモジュールのみを通過するため、機械学習による分類処理を挟んだ場合よりも転送時間を削減できます。予備実験と同様の実験により提案システムを評価した結果、実験環境では名前解決に1 - 10msを要し、この時間内に処理が終わる分類モジュールを用いれば悪性DNSクエリに対する応答を遮断できることを確認しました。また、DNSクエリの転送時間は予備実験で用いたシステムよりも削減されることを確認しました。
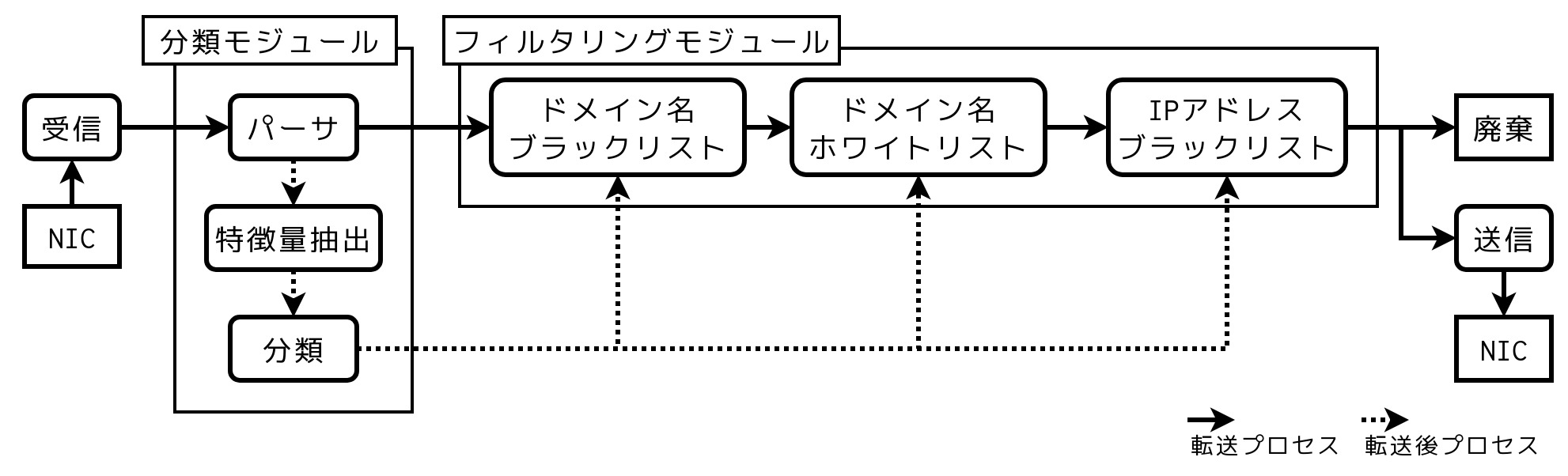
図2 DNSの名前解決時間を活用した提案システム
検知対象の拡大・複数の分類モジュールの並列化など、研究目標の実現のためにはまだまだ解決すべき課題がたくさんありますが、修了までに1つでも多く解決できるように頑張ります。
(2019年3月)
量子情報の転送を用いた量子通信は次世代の安全な通信技術として注目されており、将来の実用化に向け、多くの研究者が課題の解決に取り組んでいます。今回は、より効率的な量子ネットワークの実現を目指して研究を進める若手研究者を紹介します。

慶應義塾大学大学院
村井研究室 修士課程 松尾 賢明(まつお たかあき)
慶應義塾大学大学院 村井研究室 修士2年の松尾賢明です。2016年の2月にWIDEプロジェクトに参加し、現在は主にワーキンググループ AQUAにて量子通信に関連した研究を幅広く行なっています。WIDE2018年秋合宿研究会ではエンドツーエンド量子通信の確立に関する研究のポスター発表や、量子計算/通信をテーマとしたBoFを主催しました。
Network coding is a communication technology used for alleviating bottlenecks in a network to improve the aggregate throughput. The most basic topology that is solvable by network coding is known as the butterfly network. The classical form was discovered by Ahlswede, Cai, Li, and Yeung [1].
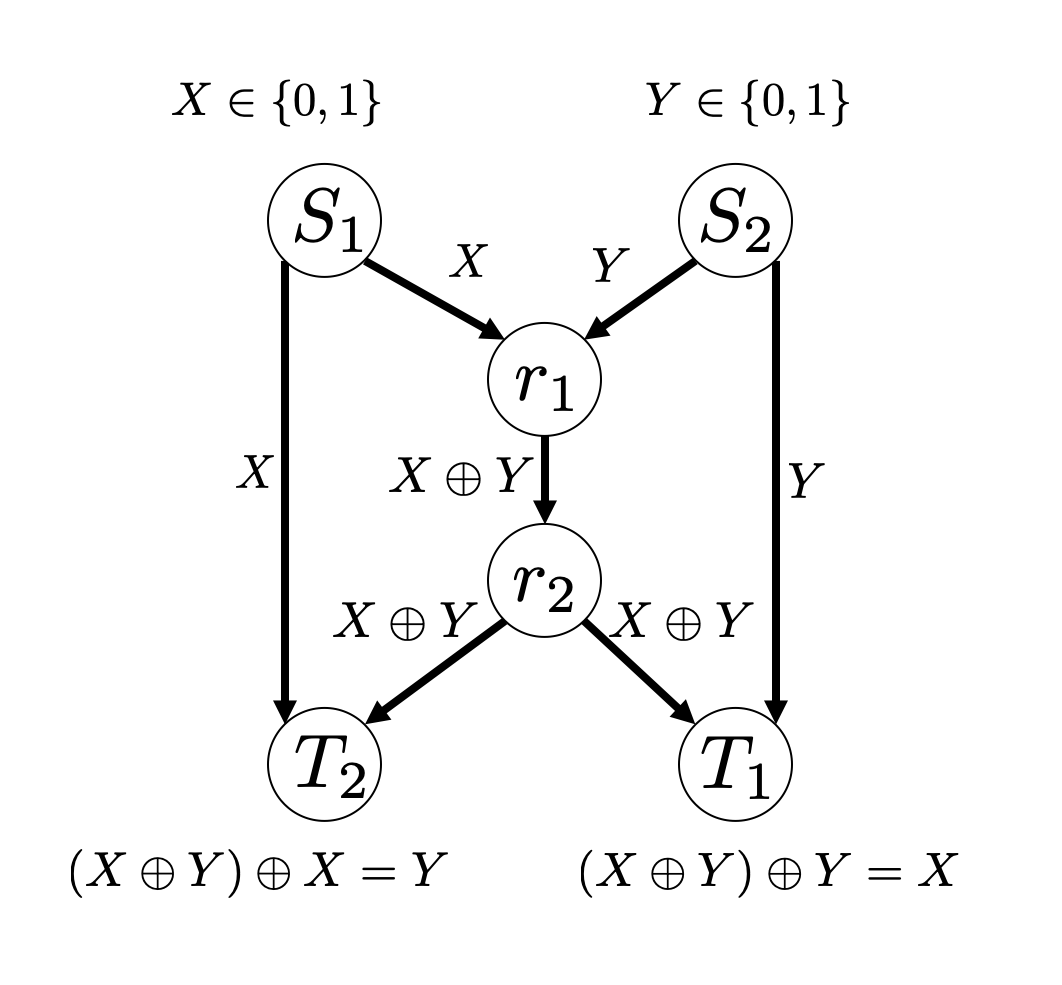
Network coding over a butterfly network
In the above example, source nodes \(S_{1}\) and \(S_{2}\) each own a 1-bit of data, \(X\) and \(Y\), with the goal of delivering them to target nodes \(T_{1}\) and \(T_{2}\) respectively. Assuming that each link has a capacity of 1 bit per unit time, the link between intermediate nodes \(r_{1}\) and \(r_{2}\) becomes a bottleneck - both X and Y cannot be delivered to \(r_{2}\) from \(r_{1}\) at the same time.
For such cases, network coding allows us to transmit both messages simultaneously. As in the figure above, each source node forwards the message to both adjacent nodes. The intermediate node \(r_{1}\) linearly combines the messages, X and Y, using an XOR operation, and forwards the encoded message to both target nodes \(T_{1}\) and \(T_{2}\) via \(r_{2}\). In the end, the target nodes can reconstruct the original message by decoding the encoded message.
Similar bottleneck problems also occur in quantum communication. There are several quantum network coding protocols published (including work by WIDE member Takahiko Satoh), however, the main problem was that they were mainly based on the classical algorithm, which resulted in deeper circuit depth causing errors in the computation, known as infidelity. One of my research themes was to design a simpler quantum network coding scheme based on measurement-based quantum computing for quantum repeater networks. The published full paper about the work can be access here [2].
The quantum repeater is considered to be an essential component for achieving a robust quantum communication system. A quantum repeater node consumes a special type of quantum resource called entanglement to deliver arbitrary data qubits across a network.
Like a classical bit, a qubit is the smallest unit of quantum information. A single qubit can be in more than one states simultaneously, which is known as the superposition state.
$$ \def\bra#1{\mathinner{\left\langle{#1}\right|}} \def\ket#1{\mathinner{\left|{#1}\right\rangle}} \def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}\\ \ket{\psi} = \alpha \ket{0} + \beta \ket{1}\\ s.t. \mid \alpha \mid^2 + \mid \beta \mid^2 = 1 $$ The \(\ket{}\) is Dirac's ket notation for a vector. Coefficients \(\alpha\) and \(\beta\) are arbitrary complex numbers representing the probability amplitudes. The actual probability of the state can be found by taking the absolute value square of the coefficient of the term of interest.
Entangled qubits have characteristics that cannot be replicated by any classical systems. The state of a qubit that is entangled with another cannot be described independently, regardless of how far apart they are located. One of the simplest entangled states involving two qubits, is known as the Bell state, where one of the bases can be described as :
$$ \ket{\Phi^+} = \frac{1}{\sqrt{2}}(\ket{0_{A}0_{B}} + \ket{1_{A}1_{B}})\\ $$
Here, two qubits, A and B, are entangled so that their state is in a superposition state of both being \(\ket{0_{A}0_{B}}\) and \(\ket{1_{A}1_{B}}\) with equal probability (\((\frac{1}{\sqrt{2}})^2 = \frac{1}{2} = 50\%\)). Thus, measuring either of the two qubits destroys the superposition state. In the real world, qubits and its carrying information may be, for example, implemented by using single photons and their polarizations.
The process of delivering an arbitrary quantum information from one place to another by consuming an entangled resource is called quantum teleportation.
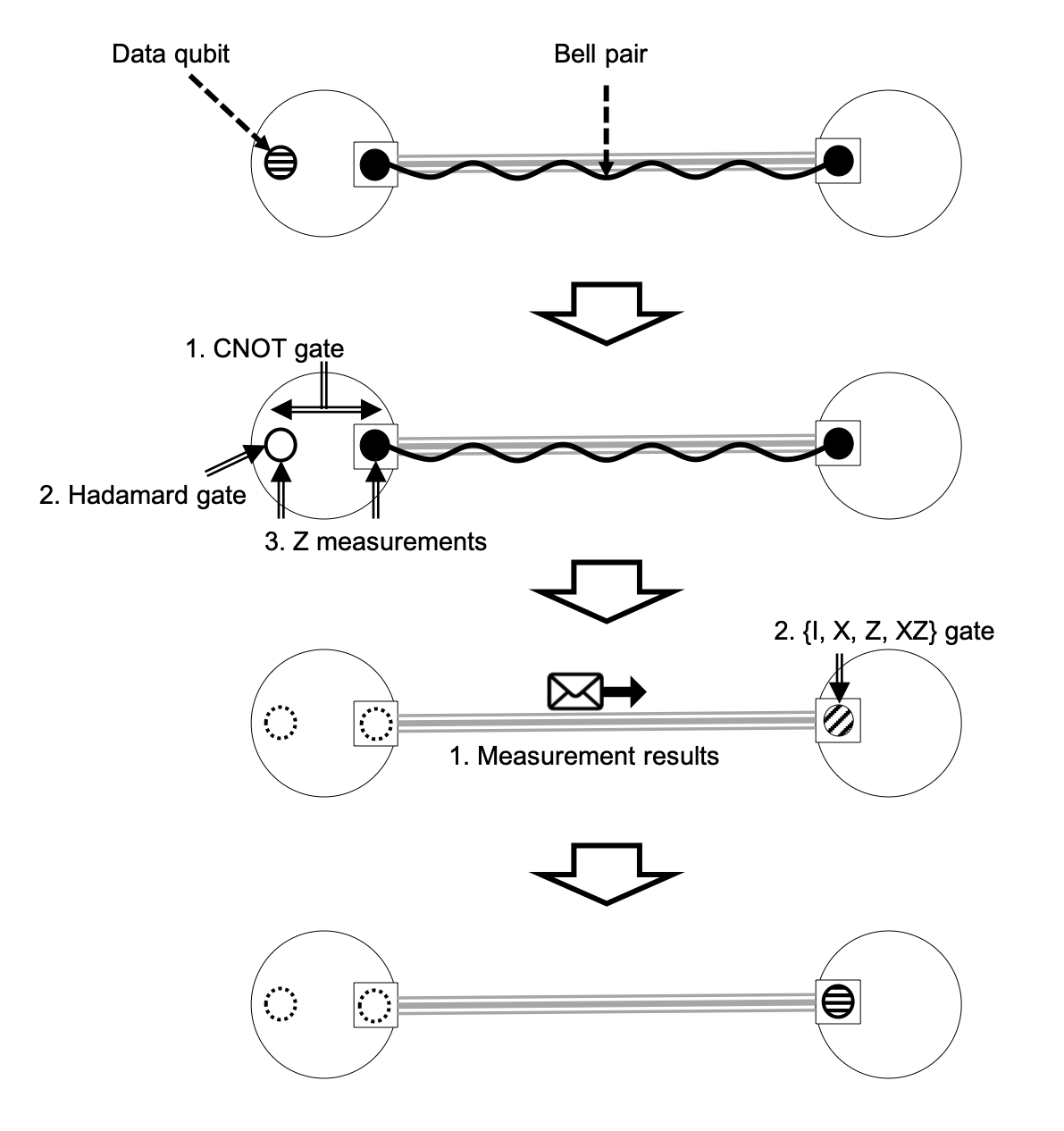
Procedure of quantum teleportation. Quantum teleportation requires classical communication for sharing the measurement results. The last gate operation depends on the received measurement results.
The CNOT gate is the quantum equivalent of the classical XOR gate. Therefore, similar to the XOR gate, we need two qubits - the control qubit and the target qubit. The CNOT gate flips the target qubit's state from \(\ket{0}\) to \(\ket{1}\) and from \(\ket{1}\) to \(\ket{0}\) if and only if the control qubit's state is \(\ket{1}\). The Hadamard gate (H gate) brings up a single qubit into a superposition state from a basis state, or vice versa. An example of its usage may be, \(H\ket{0} = \frac{1}{\sqrt{2}}(\ket{0} + \ket{1}) = \ket{+}\) and \(H\ket{1} = \frac{1}{\sqrt{2}}(\ket{0} - \ket{1}) = \ket{-}\). The X gate is similar to the classical NOT gate, and flips the bit information of a single qubit. Thus, \(X \ket{0} = \ket{1}\) and \(X \ket{1} = \ket{0}\). The Z gate, simlar to the X gate, flips the phase information of a qubit, hence resulting in \(Z\ket{+} = \ket{-}\) and \(Z\ket{-} = \ket{+}\). Because a single qubit has two degree freedoms (the bit information and the phase information), there are more than one type of single qubit measurements (X,Y and Z measurements). Though they act similarly to the classical read operation, only a part of the state's knowledge can be extracted.
For multi-hop quantum communication, the simplest strategy is to teleport the data qubit hop-by-hop. Nevertheless, this method is known to be impractical in terms of error management. Instead, we teleport one of the qubits that is entangled with another to physically lengthen the distance of the entangled resource. This technique is called entanglement swapping.
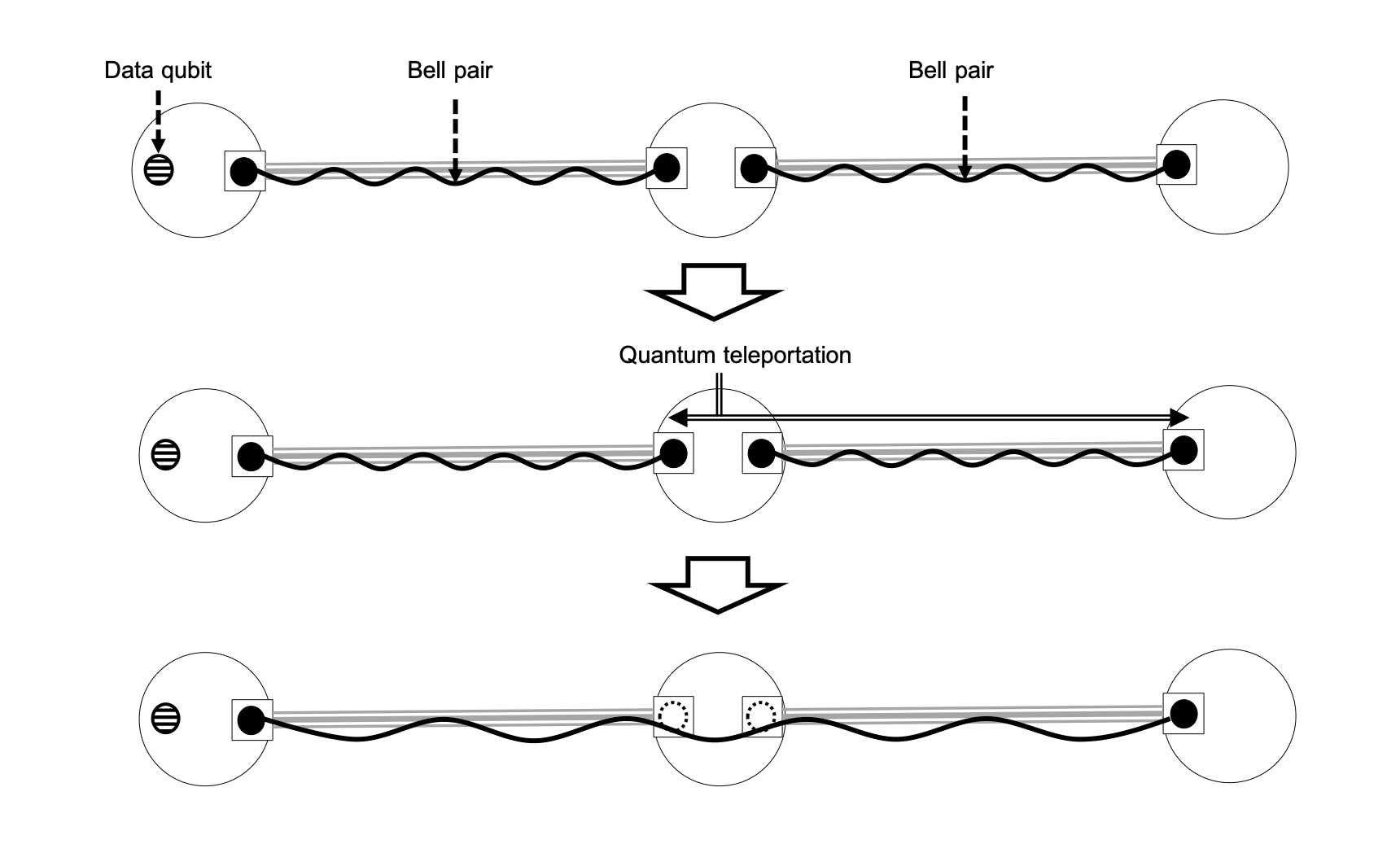
Procedure of entanglement swapping. Bell pairs along the path gets connected via entanglement swapping to directly connect the source to destination.
Without quantum network coding, the bottleneck problem over a butterfly network may be solved by multiplexing schemes, such as the time-divition multiplexing.
The goal of quantum network coding for repeater networks is to generate two crossing over resources simultaneously.
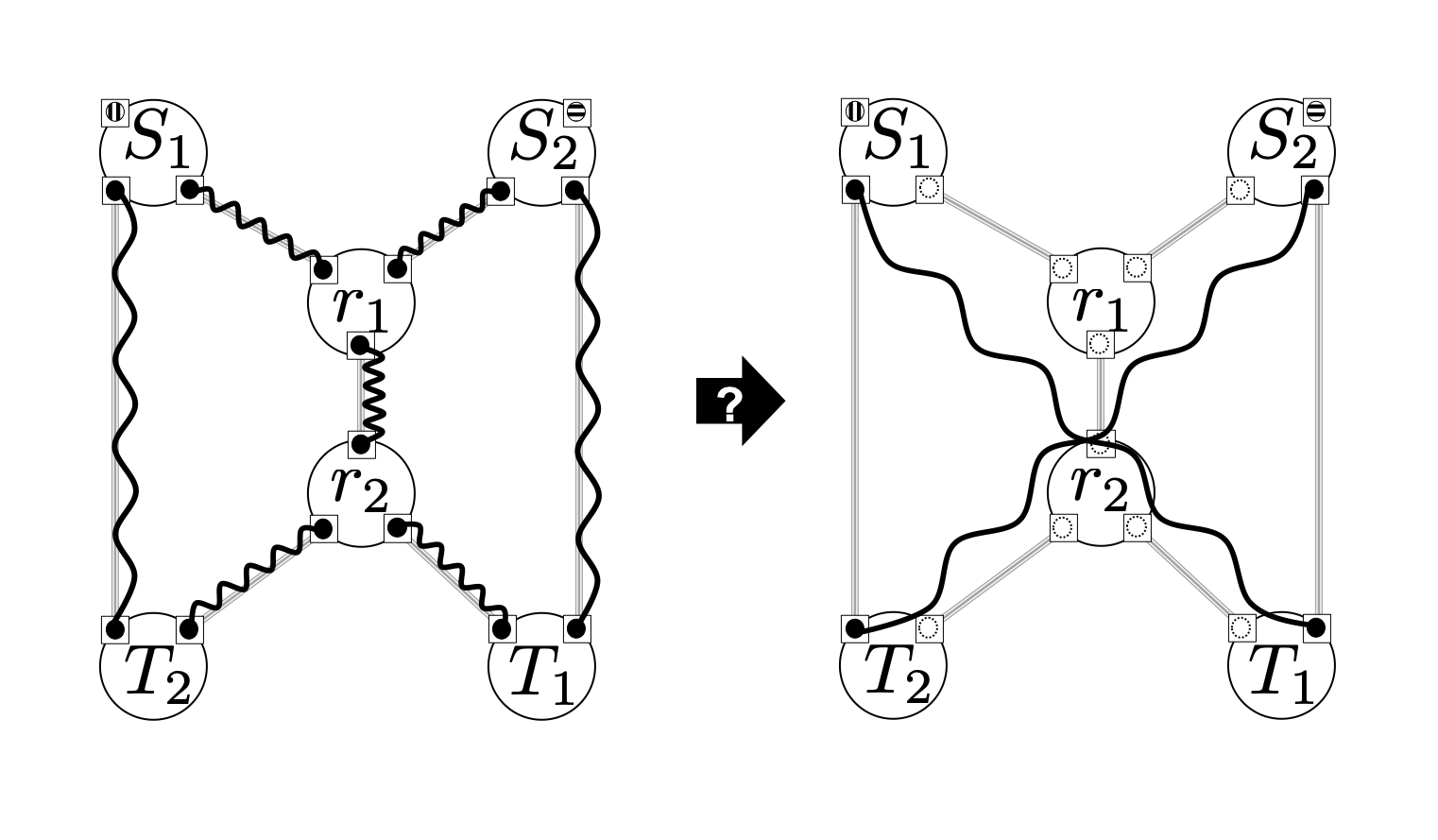
Goal of quantum network coding.
My work focused on simplifying the procedure between the input state and the output state by taking full advantage of the unique characteristics of measurement-based quantum computing (MBQC).
MBQC is an alternative universal computation scheme based on single qubit measurements over square lattice cluster states, which is commonly a system area network. Any single qubit unitary operation (e.g. X gate) can be, for example, substituted by a sequence of three measurements over a chain of four qubits.
A cluster state can be generated by preparing all qubits as \(\ket{+}\) state first, and by performing Controlled-Z gates between any qubits to make an a new edge/entanglement.
Thus, a cluster state with \(n\) qubits can be defined by :
$$ \ket{G} = \prod_{(a,b) \in E} CZ_{a,b}\ket{+}^{\otimes n} $$
where E is the set of edges/entanglement and a, b are the corresponding vertices/qubits in the cluster state. A cluster state with only two qubits, qubit A and qubit B, is \(\ket{G}=\frac{1}{2}(\ket{0_{A}0_{B}}+\ket{0_{A}1_{B}}+\ket{1_{A}0_{B}}-\ket{1_{A}1_{B}})\), which is almost equivalent to a Bell pair because \(H \ket{\Phi^+} = \ket{G}\) with the Hadamard gate applied to either qubit.
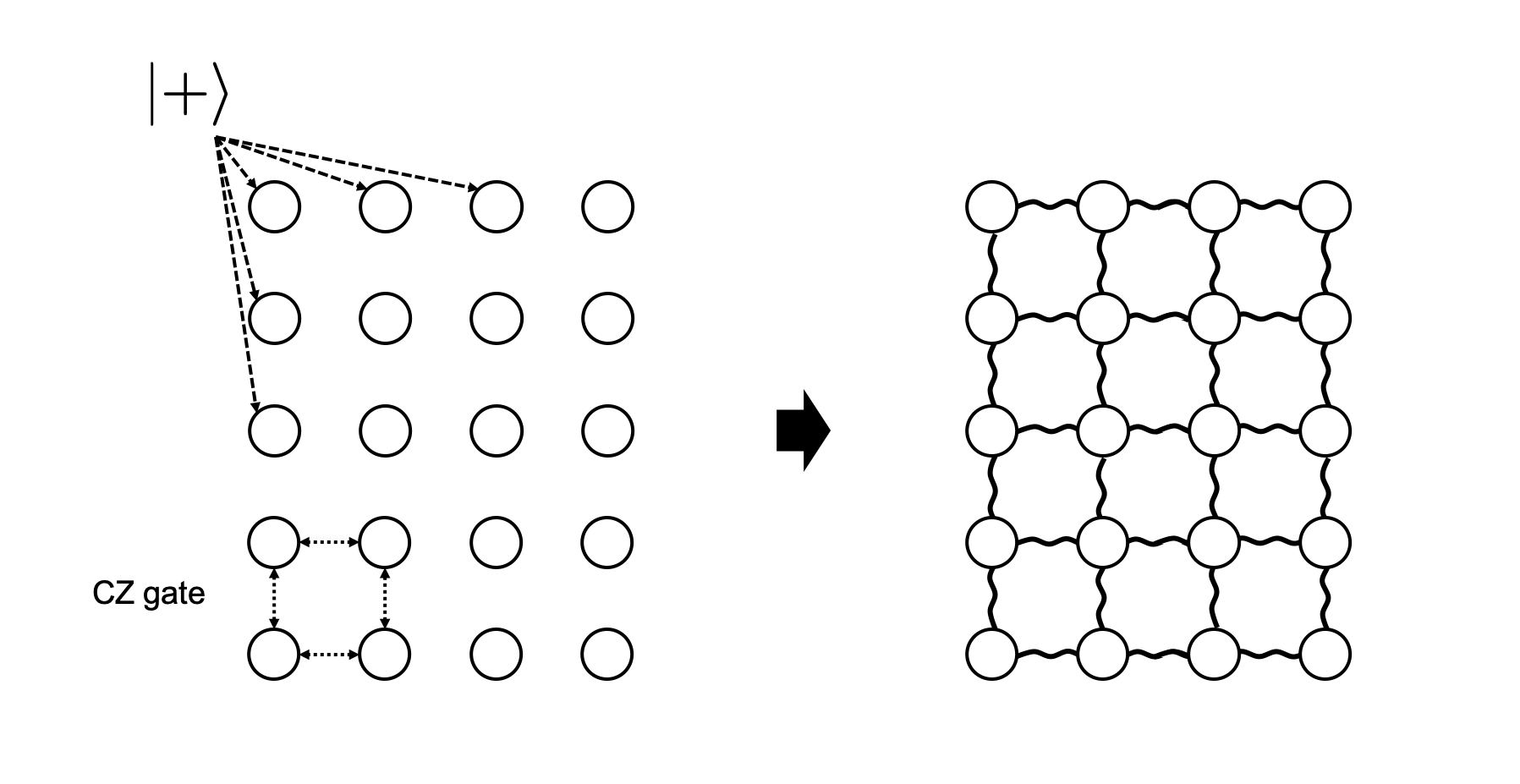
A pictorial example of a square lattice cluster state generation. In MBQC, Qubits are measured along different axis depending on the operation, from left to right concurrently.
Being able to compute solely based on measurements is indeed an interesting fact. Another characteristics, which I took advantage of in my research, is the topological transition of the cluster state caused by qubit measurements.
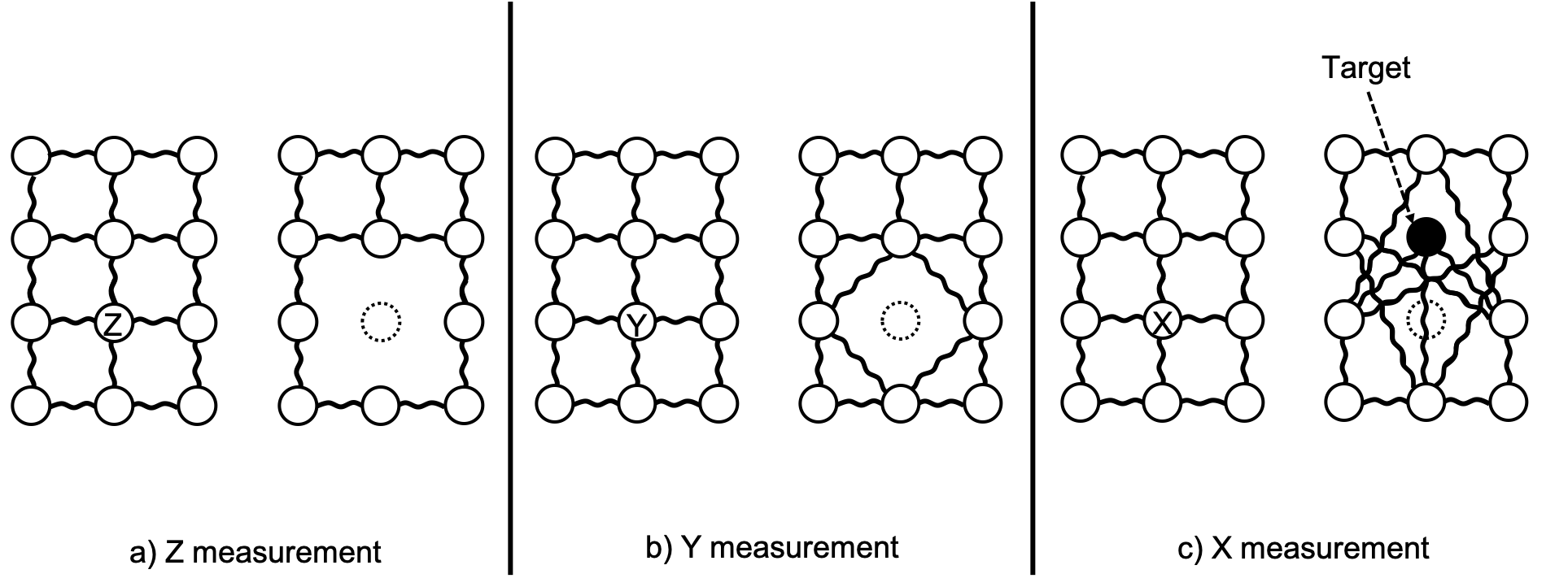
Topological transition of a cluster state invoked by a single qubit measurement. The X measurement requires an extra gate operation to one of its neighbors.
In my research, I assumed repeater nodes with the ability to distribute two qubit cluster states between adjacent nodes, and proposed/analyzed a measurement based operations on resources to directly connect both source nodes to target nodes simultaneously. Three simple steps can transform the initial state to the desired output state.
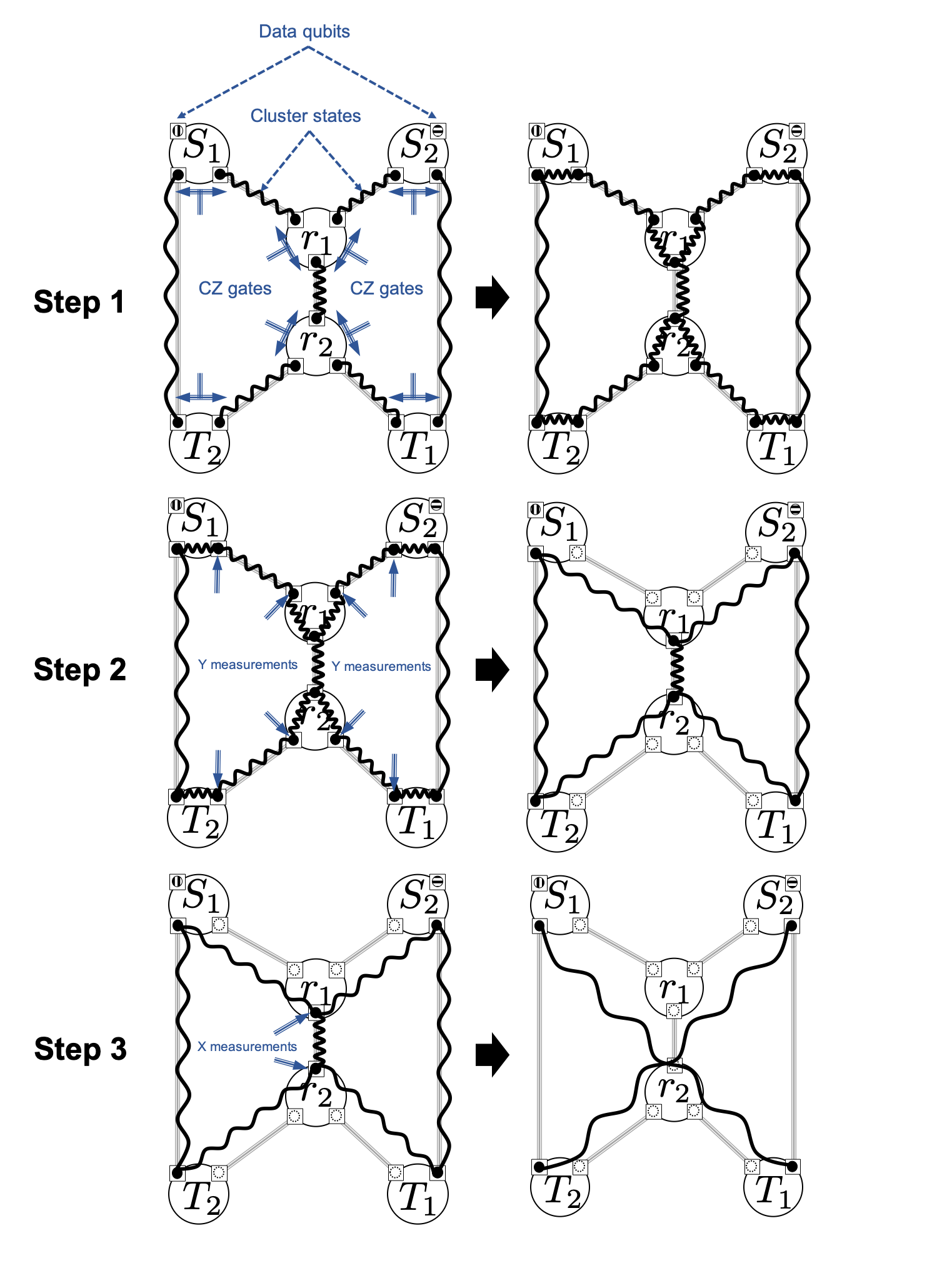
Encoding procedure of measurement-based quantum network coding.
My proposed method has successfully reduced the circuit depth by 56.5% from a previously known quantum network coding protocol [3].
I joined AQUA because I took Higher Level mathematics, physics and computer science for the IB program in back high school, and wanted to use everything I learned at the same time.
It is simply very interesting and challenging for me to come up with ideas and solutions that completely differ from the classical systems. Quantum computing/communication is still under development, but they are growing very rapidly nowadays. Today, we have access to one of the best quantum computers in the world, developed by IBM, and have tremendous opportunities to work on the real world problems. It is one of the most exciting times I have, to be able to actually contribute to the very deepest core of the next generation technology.
Currently, I am working on building a quantum Internet simulator. In the future, I expect the simulator to be able to analyze various protocols, including quantum network coding, to gain new knowledge with more details.
If you are interested in quantum networking, please contact to AQUA(aqua@sfc.wide.ad.jp) or to me (kaaki@sfc.wide.ad.jp) directly.
[1] R. Ahlswede, N. Cai, S. Y. Li, and R. W. Yeung, IEEE Trans. Inf. Theor. 46, 1204 (2006).
[2] T. Matsuo, T. Satoh, S. Nagayama and R. Van Meter, Phys. Rev. A 97, 062328 (2018).
[3] T. Satoh, F. Le Gall, and H. Imai, Phys. Rev. A 86, 032331 (2012).
(2019年4月)
WiFiを利用した公衆無線LANサービスは外出先でインターネットを利用する手段のひとつとして広く利用されています。公衆無線LANサービスでは、多くの場合 Captive Portalと呼ばれる利用者認証の仕組みが導入されています。今回は、このCaptive Portalが抱えるセキュリティの懸念を調査し、より安全な公衆インターネットサービスを目指す研究者を紹介します。

東京大学大学院 情報理工学系研究科 創造情報学専攻
江崎・落合研究室 修士課程 増田 英孝(ますだ ひでたか)
東京大学大学院 情報理工学系研究科 創造情報学専攻 江崎・落合研究室 修士1年の増田英孝です。WIDEプロジェクトには2018年の5月から参加しています。2019年春のWIDE合宿では卒論を題材に研究発表を行いました。今回はその卒論の内容をご紹介します。
公衆無線LANサービスは2002年頃に運用が開始され、現在では公共交通機関やコンビニなど街のいたるところで利用できます。公衆無線LANが広く普及する一方で、これを利用した不適切な活動を防止するために、様々な利用者を認証する機能の導入が進められています。ただ乗りの防止などが主な目的であり、多くの公衆無線LANサービスにおいて、Captive Portalを用いた認証機能が導入されています。

Captive Portalを利用すると、特殊なソフトウェアなしでブラウザなどからユーザ登録・認証等が簡単に行えます。接続した端末は認証が済んで初めて外部と通信ができるようになります。認証が済んでいない端末は、Captive Portalによって認証と関係ない全ての通信を遮断されます。しかし、Captive Portalの中には設定の不備により、ICMP・DNSなどの通信が遮断できていないものが存在します。ICMPは疎通確認、DNSは名前解決に使われるプロトコルで、一見するとその通信が遮断されないからといって大した害はないように思われます。しかし、Covert Channelを利用すると、ICMPやDNSといったプロトコルで不正な通信ができてしまいます。これが悪用されると、一部の公衆無線LANは不正な利用者に認証を迂回され、勝手に使用されてしまいます。
公衆無線LANの不正利用で困るのは、ただ乗りされる通信事業者だけではありません。例えば以下のような場合、公衆無線LANの届く範囲にいる誰もが危険に晒されています。ある企業のネットワークにコンピュータウイルスが侵入し、機密情報を入手したとします。しかし、そのネットワークは外部への通信を監視しているので、通常の方法では機密情報を外部へ送信できません。そこで、入手したデータを外部へ送信する経路として、公衆無線LANが使用される可能性があります。すると、たとえ通信を監視していたとしても、その監視の目の及ばないところからデータを外部へ送信されてしまいます。

このような不正利用の危険性のある公衆無線LANの存在はすでに知られていましたが、その実態に関する研究はなかったので実際に自分の足で調査してみました。
暗号化されていないアクセスポイントに実際に接続し、認証が済む前にICMP・DNSで通信ができるかを調べました。Raspberry Piを自分で持ち歩き、調査は東京都・神奈川県で15日間かけて行いました。

その結果、のべ1148個、合計955個のアクセスポイントについて調査ができました。 認証前にICMPを遮断していないものは48.3%、DNSを遮断していないものは72.5%でした。そして、72.6%のアクセスポイントは不正利用の危険性が存在することが確認されました。不正利用リスクのある公衆無線LANの割合は自分が想定していたよりも高く驚きでした。
| ICMP | DNS | 個数 |
|---|---|---|
| ○ | ○ | 460 |
| ○ | × | 1 |
| × | ○ | 232 |
| × | × | 262 |
データの精度を高める必要があります。アクセスポイントによっては、可能な通信の種類が日によって異なることがありました。これは、機械とアクセスポイントの通信が切断されてからそのことを認識するまでの時間差が原因だと考えられます。一度通信に成功したプロトコルで通信できるかを最後にもう一度確認することで、この問題は解決できるはずです。また、接続したアクセスポイントがCaptive Portalであることを確認する必要もあります。
公衆無線LANの不正利用への対策はあまり進んでいないことがわかりました。しかし、通信事業者が対策を行うメリットは少ないので、対策を動機づけるような制度の構築が必要だと感じました。
(2019年5月)
ネットワークサービスはもやは私たちの生活と切り離すことができない基盤になりつつあります。クラウド技術などの発展により、簡単に新しいサービスを送り出すことができるようになったため、サービス利用者の認証認可を安全に実現する仕組みが重要になっています。今回は、サービス開発の現場で、開発者に大きな負担をかけることなく、様々な認証認可方式を導入するための基盤技術に取り組んでいる研究者を紹介します。

慶應義塾大学大学院 メディアデザイン研究科 Network Media
後期博士課程 加藤 大弥(かとう だいや)
慶應義塾大学メディアデザイン研究科 Network Media Project 所属 後期博士課程 加藤 大弥です。WIDEプロジェクトには、2018年の2月から参加しています。2019年秋のWIDE合宿では期間中の会場ネットワーク構築の指揮を執らせていただいています。
同研究科において学生に対して検証用インフラの整備・提供を行っており、その中でもサービスを利用するうえで必要不可欠な認証認可基盤の研究・取組みについて紹介いたします。
私たちの日常生活においてインターネット上のサービスを利用することは当たり前になりました。その中で自分に適した・自分専用の情報を取り扱うために個人を識別することが必要不可欠になり、その多くが利便性に優れているパスワードを利用したものでしょう。
パスワードはユーザーが覚えておくだけで利用することが可能であり、キーボードからの入力のみで認証を行うことが可能な利便性に優れた認証方式です。反面、ユーザーが生成するパスワードの単語的な偏り、覚えておくことが可能な文字の長さが限られているといった点から解析が容易になりつつあるという問題点を抱えています。また、2017年に改定された、NIST SP800-63-3 Digital Identity Guidelines (https://pages.nist.gov/800-63-3/)による世界的なパスワード運用ポリシーに大きな影響をあたえたことで、パスワード以外の認証方式にも注目が集まるようになり始めました。
上記の問題以外にも大学間、特に学生間で発生する問題も存在しています。多くの大学では、授業支援・研究支援・出席管理といったサービスを学生生活をサポートするために展開しています。しかし、学生の中にはITリテラシーが未熟で簡単なパスワードを使いまわす、パスワードを他人と共有するといった行動が見られることがあり、これを原因とした個人情報の漏洩等の大きな問題の発生が懸念されています。しかし、学生に対してむやみやたらにパスワードを変更させたり、覚えることが困難な長いパスワードを利用させることは、学生のサービス利用を著しく妨げる恐れがあり、一概に適切な解決策とは言えません。
コンテナ技術の普及やクラウド開発の発展で誰でも簡単に最低限の知識、リソースでサービスを開発できるようになり、学生主導で学内向けサービスを開発・展開することも多くみられるようになりました。学園祭の開催ページや部活動・サークル活動でのECサービス等がこれにあたります。しかし、これにより、学生が大学で利用しているユーザーアカウントを用いてサービスを利用し、そのユーザー情報をサービス開発した学生が管理するといった構図が生まれます (図1)。実装、運用面で必ずしも専門的な知識と経験を持っているわけではない学生が構築したサービスから、学内で利用している個人情報が漏れだすリスクがあるのではないかと考えられます。

図1. 学内サービスと個人情報の管理
そこで本研究では、学生に、
を目標に図2に示すような、学内向けの認証認可基盤の開発・運用を行っています。また、パスワードレス認証、多要素認証、FIDO、WebAuthnなどのさまざまな認証を提供することで、ユーザーに適した認証の実現を目指しています。例として実際に学生に対して提供しているOIDCベースの認証画面を図3に示します。(2019/06/04現在)

図2. 学内に展開している認証認可基盤

図3. 実際に提供している認証画面 (※実際の認証状態が含まれるため一部修正済)
認証認可基盤を誰もが適切に運用可能になるための研究にも取り組んでいます。もし、明日突然私が認証認可基盤を運用できない状態になってしまった場合、基盤全体が使えなくなってしまっては本末転倒です。そこで、継続的なインテグレーションとデプロイ(CI/CD)や障害が発生した場合に技術力の異なる運用者全員がデバックできるような仕組みが必要不可欠です。そのために、認証基盤の設定のCode化や認証認可基盤間での認証情報の共有について取り組んでいます。
WIDE Projectでは、「左手に研究、右手に運用。」という理念があります。認証認可の研究においても複数の要素の強靭な認証を実装することである一定程度の強固な認証を提供することができます。しかし、それではユーザーが使いにくく結果として利用されないということが起こりえます。そこで実際の運用を通してユーザビリティの担保や使いやすい認証を追求していくことが必要です。
認証認可技術は、「ログインできました。」「ログインできませんでした。」という結果だけが優先されてしまいがちな少々味気ない研究分野と思われるかもしれません。しかし、ここに至るまでの研究と運用のバランス感覚の追求こそが認証認可研究の醍醐味であり腕の見せ所なのです。ぜひ、明日から認証認可技術に目を向けてみてください。そして、興味があれば一緒にやりましょう。
(2019年6月)
コンピュータネットワークの発展に伴い、コンピュータやIoTデバイスを対象としたサイバー攻撃が増加しています。これらの攻撃に対応できる高度なセキュリティ人材が求められていますが、そういった人材は常に不足気味です[1]。優れたセキュリィ人材は座学だけで育てることはできません。実践的な演習を通して実際の攻撃や対策などを体験することにより、知識や経験を身に付ける必要があります。今回は、人材育成のための演習に使われるサイバーレンジの構築・運用技術に取り組む研究者を紹介します。

北陸先端科学技術大学院大学
知念研究室 博士前期課程 砂川 真範(すながわ まさのり)
北陸先端科学技術大学院大学 知念研究室 修士課程の砂川真範です。サイバーレンジの研究をしています。WIDEプロジェクトには2016年の7月から参加しています。WIDEでの主な活動としては、2017年の研究会、2018夏の研究会、2019夏の研究会で運営および会場ネットワーク構築などに携わりました。また、2018年4月にはサイバーレンジをテーマにしたワーキンググループ、Nebucha (ネブカ)ワーキンググループ(NBCA-WG)を設立しました。その他の活動としては、2017年のSECCON決勝大会でSECCON YOROZU (よろず屋)やInteropへの出展を行なっています。普段の生活でもクラスタの構築、研究室ネットワークの管理・運用を行なっています。
ここでは、NBCA-WGで定義しているサイバーレンジを説明します。サイバーレンジとは、セキュリティ演習を目的とした、主に計算機上に作られた仮想空間です。
サイバーレンジを製品やサービスとして提供している組織もありますが、いずれも有償であったり、ソースコードや動作の仕組みが公開されていません。そのため、わたしたちのチームでは北陸先端科学技術大学院大学(JAIST)のサイバーレンジ構成学講座(CROND)が修正BSDライセンスのOSS(オープンソースソフトウェア)として提供しているCROND Cyber Security Training System (以下、CSTSと表記)[2]をベースに研究を進めています。
CSTSとは、JAISTのCRONDが提供している、セキュリティ演習用のシステムです。CSTSは、主に以下の3つ要素で構成されています。
CyRIS、CyLMS、CyTrONEのそれぞれが連動して動作します。
まず、CSTSを用いたサイバー演習の流れを説明します。はじめに、トレーナーがCyTrONEのユーザインターフェイスを操作してサイバーレンジ作成の指示を出します。この指示を受けて自動的にサイバーレンジが構築されます。サイバーレンジにはそれぞれ実習のためのクイズが用意されています。作成されたサイバーレンジの番号がCyTrONEのユーザインターフェイスに表示されるので、受講者はクイズの内容を確認し、対応した演習環境にアクセスして演習を行います。
次に、CSTSを用いたサイバー演習をの内部動作を説明します。トレーナーがCyTrONEのユーザインターフェイスからサイバーレンジの構成とクイズをセットにしたトレーニングコンテンツと受講者の人数を送信します。CyTrONEはトレーニングコンテンツをサイバーレンジの構成とクイズとに分割しCyRISとCyMLSに渡します。渡された情報を元に、CyRISは必要な仮想マシンを作成し、サイバーレンジを構成します。同様に、CyMLSはクイズの内容をLMSに登録します。

ここでは私が、日々研究し取り組んでいるHack祭(ハクサイ)を紹介します。
Hack祭とは、インシデントの再現を目的としたサイバーレンジ構築支援システムです[3]。セキュリティインシデントが発生した際は、脅威情報構造化記述形式であるSTIXやMISPなどでインシデント内容を記述し情報の共有などが行われます。Hack祭では、それらで記述された内容を使用して、インシデント発生時に近い状態をサイバーレンジで再現します。Hack祭で構築されたサイバーレンジを使用することにより、過去のインシデント事例を使用したサイバー演習(セキュリティ演習)や 対応の振り返りなどが容易に実現できます。

Hack祭では、様々なインシデントに対応できるよう汎用性を持たせる必要があり、機能ごとにサブシステム化されています。例として、メインとなる統合管理について説明します。統合管理ではインシデントデータを解析します。その際、記録に欠損があり補完可能な場合には補完を行います。そして、項目ごとにそれらの機能を有するサブシステムに対して作成や実行などの操作を指示します。それらの結果に基づき次の操作を指示します。これにより、Hack祭利用者は依存関係などの順序を意識したり、自分で定義することなく使用できます。他にも様々なサブシステムがあります。
現状では、サイバーレンジを使用する場合、一定以上の性能をもつコンピュータクラスタが必要です。そのため、気軽にセキュリティ演習を実施できません。NBCA-WGでは、現在のクラウドサービスのように、「いつでも・どこでも・だれでも」気軽に使えるサイバーレンジのサービスとしてCRaaS (CyberRange as a service)の実現を目指しています。日々、普及活動や、より使いやすく高機能なサイバーレンジ構築支援システムの研究・開発を行なっています。
Nebuchaワーキンググループ(NBCA-WG)では、WIDEにおけるサイバーレンジの議論と実装、普及活動などを行なっています。2018年度は、サイバーレンジの議論をする上で、認識を共通化するために必要となる「用語集」の作成やセキュリティ演習の舞台裏の解説、CSTSの導入相談、さらには製品として提供されているWIDE外の組織が持つサイバーレンジの見学・意見交換などを行いました。 2019年度は、サイバーレンジの分野マップ作りや、セキュリティ演習用コンテンツ(カリキュラム)作り、CRaaSを可能とする次世代セキュリティトレーニングシステムに関する議論・実装など予定しています。
セキュリティ演習やサイバーレンジに少しでもご興味がありましたら、是非NBCA-WGにご参加ください。また、OSSのソフトウェアとして無償で使用可能なCSTSの導入相談も受け付けています。
[2] CROND Security Training System GitHubページ
[3] インシデントの再現を目的としたサイバーレンジ構築支援システムの提案
(2019年8月)
Bitcoinの基幹技術として提唱されたブロックチェーンは、中央管理者を持たない自律分散環境において整合性の取れた情報を共有するための仕組みであり、様々な分野での応用が期待されている分散台帳技術のひとつです。仮想通貨の分野で広く利用されているブロックチェーンですが、まだ新しい技術であり、現実的な運用や応用のための研究が続いています。今回は、ブロックチェーン技術の運用技術・応用技術の研究開発に取り組む研究者を紹介します。

慶應義塾大学大学院
政策・メディア研究科 博士課程1年 村井純研究室 阿部 涼介 (あべ りょうすけ)
慶應義塾大学大学院政策・メディア研究科博士課程1年 村井純研究室所属の阿部涼介です。学部生の頃からブロックチェーンをテーマに研究を続けています。ブロックチェーンは、Bitcoinの基幹技術として発明された「中央管理者なしに改ざん困難な台帳を形成する技術」です。本コラムでは、ブロックチェーンの概要と現在の課題、そして私の取り組む研究を紹介します。
Bitcoinを例に挙げながら、ブロックチェーンの概要を説明します。通貨システムでの支払いを考えると、支払った通貨は過去にすでに支払い済みの通貨をコピーしたデータ、すなわち偽造通貨を使った「二重支払い」ではないか確認する必要があります。Bitcoinでは過去の支払いを全て管理・記録する台帳を用意することで、二重支払いの確認が可能になると考えました。ここで、過去の支払いを全て管理・記録する台帳は、誰が管理するべきでしょうか?もし、特定の管理主体に任せた場合、検証作業において不正を行わない保証はありません。これは誰が認証局になるか、といったインターネット上における「トラスト(信頼)」の問題の一種です。この問題を解決するために、Bitcoinでは、この台帳を全てのノードが自律的に作成、更新を行い、第三者の検証機関を置かずに通貨システムを実現しました。この全てのノードが持つ台帳が「ブロックチェーン」です。

ブロックチェーンでは、一定期間の取引データをひとまとまりにしたデータを「ブロック」として作成します。Bitcoinではブロックの作成には、計算コストがかかる数学的パズルを解く必要があります。また、ブロックには、直前のブロックの要約値(暗号学的ハッシュ値)が含まれています。そのため、過去の支払いを改ざんすると、当該ブロックの後に連なるブロック中の要約値が全て変化します。この連鎖構造により、最新ブロックまで全てのブロックを書き換える必要があります。この時チェーンは2本に分岐しますが、典型的には最長のチェーンが正しいチェーンと認識されます。したがって、チェーンを全て再構築するには各ブロック作成のための膨大な計算パワーが必要になる上、ネットワーク上の他のノードたちは改ざん前のチェーンに対してブロックを作成しているため、いち早くブロックを作成し続ける必要があります。そのため、改ざんの成功にはネットワーク全体の50%以上の計算パワーが必要となると言われています。

ブロックチェーンを用いることで、特定の第三者に依存せずにデータが改ざんされていないという信頼性を付与することが可能です。その応用範囲は広範囲に広がると考えられており、ホットトピックの一つとなっています。分散システムの分野には、複数の矛盾するデータから「正しいデータ」を選択する合意形成アルゴリズムがあります。しかしながら、旧来の合意形成アルゴリズムは参加者のネットワークサイズによっては動作が困難になるという問題がありました。一方、ブロックチェーン技術を利用した分散合意形成はBitcoinをはじめとした複数のサービスで採用され、全世界レベルで動作しています。
しかし、ブロックチェーンも未だ完全な技術ではありません。ブロックチェーンで保証される改ざん困難性は確率的なものです。そのため、現在「正しい」とされているものが否定される可能性が常に残り続ける「ファイナリティの問題」があります。また、現状のBitcoinでは1秒間に処理できる取引数は7取引と言われており、処理性能をどう向上させるかという「スケーラビリティの問題」があります。
現在、ブロックチェーン応用の検討とブロックチェーンを広範囲に応用できる技術とするための基盤技術としての研究に並行して取り組んでいます。
学部の卒業論文では、個人が3Dプリンタを用いて自律分散的にものづくりを行うパーソナルファブリケーションと呼ばれる活動の中で、どのように製造物の情報を担保するか、という部分にブロックチェーンの応用を検討しました。製造時にブロックチェーン上に製造物の設計図、設計者、製造者の情報を書き込むことで、自律分散的な仕組みを維持しながら、製造物情報の完全性の保障を検討しました。3Dプリンタへ接続したRaspberry Piをブロックチェーンノードとすることで、製造時にブロックチェーン上へデータの書き込みを行う実装を行いました[1]。

修士論文では、ブロックチェーンノードのストレージに着目した研究を行いました。卒業論文での実装では、Raspberry Piをブロックチェーンノードとしましたが、ノードは世界中で発行された新規のデータを全て保存する必要があります。ブロックチェーンは追記専用の台帳であり、保存すべきサイズは増加し続けます。そのため、今後スマートフォンなどのストレージ容量の限られたデバイスでは動作困難になると考えられます。そこで、クラスタ上でデータの割り当てと読み出しを自律分散的に行う仕組みであるDHT(分散ハッシュテーブル)を用いて、ブロックチェーンデータを分散的に保持することで、ストレージの負荷分散を行う手法である「KARAKASA」を提案しました。対障害耐性を担保するレプリケーション(複製)を行うことで、自律分散的な動作を失わずに、負荷分散を行うことが可能であることを検証しました[2]。

ブロックチェーンは今までのシステムとは異なるトラストモデルを提供し、金融をはじめとした様々な分野での応用が検討されています。その一方で、本コラムで触れたものをはじめとして、様々な課題が置き去りになったまま社会の中での応用検討が進んでいるように見受けられます。私の所属研究室では学術研究用のネットワークであるBsafe.network[3]のノードを運用し、その経験を活かして改めて課題の整理などに取り組んでいます。そうした活動を通じて、WIDEプロジェクトの中でも「右手に運用・左手に研究」の元に、基盤技術としてのブロックチェーン自体の改善と応用検討を両輪として進めていきたいと考えています。
[1] 阿部涼介, 斉藤賢爾, 村井純. "パーソナルファブリケーション時代における Blockchain を用いた製造情報保存システム." マルチメディア, 分散協調とモバイルシンポジウム 2017 論文集 2017 (2017): 1045-1054.
[2] Ryosuke Abe. "Blockchain Storage Load Balancing Among DHT Clustered Nodes." arXiv preprint arXiv:1902.02174 (2019). https://arxiv.org/abs/1902.02174
[3] Bsafe.network http://bsafe.network/
(2019年10月)








